Bayesian modeling of StarCraft II ladder performance
In this post, I’m going to use PyMC3 to analyse my 2019 StarCraft II ladder games. In particular, I’m going to look at the relation between MMR - MatchMaking Rating, a metric of ladder performance - mine and that of my enemies - and what it can tell us about my win chances.
bayes
pymc3
starcraft
python
StarCraft II Bayesian replay analysis
Published
June 10, 2020
I’ve been in a bit of a pickle recently. I really need to figure out Bayesian inference as practice for my masters’ thesis. I’ve been wondering, what kind of cool project - hopefully with my own data - could I make?, I thought as I fired up StarCraft II in the evening, as I usually do to unwind nowadays. What kind of fun use of PyMC3, the neat Python library for probabilistic programming, could I showcase?, I wondered as I watched my ladder ratings fall from the distraction. What kind of useful knowledge could I try to acquire using it?, I thought, watching my game performance fluctuate over the course of months.
And then it hit me.
In this post, I’m going to use PyMC3 to analyse my 2019 StarCraft II ladder games. In particular, I’m going to look at the relation between MMR - MatchMaking Rating, a metric of ladder performance - mine and that of my enemies - and what it can tell us about my win chances.
A few facts about StarCraft
SC2 is a fast-paced real-time action/strategy game played competitively all over the world;
Each game of SC2 lasts about 10-30 minutes;
There are three races in SC2, which means factions, each with a completely different playstyle and toolset; I play Protoss (the advanced space aliens) and the other two suck are Terran (scrappy future humans) and Zerg (hivemind insectoid aliens).
There is no tribal animosity between players of the races in the community whatsoever.
Each 1v1 game pits two randomly selected players of similar MMR. Better players have higher MMR, and it’s used to find worthy (adequate) opponents for you. A Protoss player has three different possible matchups - Protoss vs Protoss (PvP), PvT and PvZ.
A few facts about Bayesian inference
it’s an alternate, computationally intensive approach to statistics (of which you probably know frequentist statistics)
it’s a really neat tool to formulate complex models of processes occuring between entities
it can let you infer knowledge about quantities not directly included in your data at all (so-called “latent” quantities)
it can combine data with your initial assumptions (“priors”) or initial beliefs about quantities in your system
this means you need to explicitly state what you believe about the data first
it returns probability distributions for your parameters, rather than simple point estimates like means or variances
this makes handling asymmetric uncertainties and error bars much easier
it’s a great framework for learning new knowledge from data, as I’ll try to show
In this post, we’re going to use my own dataset of ladder replays. The motivation is this: there are days when I play terribly and there are days when I play my heart out. It does, however, feel like my performance fluctuates a lot. I thought I could use Bayesian modelling to learn something about these fluctuations.
I was going to have an example of pulling this data using ZephyrBlu’s replay parser library and an unreleased custom wrapper I have for that. However, since I’m getting a ton of warnings that would distract from the main ideas, in the name of simplicity I’ll just post the parsed version on GitHub. I’ll come back to parsing those once I finish that library of mine.
import pandas as pddf = pd.read_csv("https://raw.githubusercontent.com/StanczakDominik/stanczakdominik.github.io/src/files/replays.csv", index_col=0)df['time_played_at'] = pd.to_datetime(df.time_played_at)df
time_played_at
win
race
enemy_race
mmr
mmr_diff
enemy_nickame
0
2020-05-27 10:32:29+00:00
True
Protoss
Terran
4004
-169
giletjaune
1
2020-06-09 17:11:15+00:00
False
Protoss
Zerg
4186
39
djakette
2
2020-02-02 17:27:27+00:00
True
Protoss
Terran
3971
58
Syocto
3
2019-12-20 18:53:00+00:00
True
Zerg
Terran
2984
-106
Jason
4
2019-12-09 20:36:21+00:00
True
Protoss
Zerg
4015
-9
<OGCOСK><sp/>ShushYo
...
...
...
...
...
...
...
...
432
2019-11-04 20:53:20+00:00
False
Protoss
Terran
3800
-83
<MiClan><sp/>MiSHANYA
433
2020-05-04 12:43:06+00:00
True
Protoss
Terran
3926
95
StaMinA
434
2020-02-02 17:15:06+00:00
False
Protoss
Zerg
4012
-80
<0mg><sp/>Sroljo
435
2020-04-19 11:48:32+00:00
True
Protoss
Zerg
0
0
shadowofmich
436
2020-04-30 18:34:01+00:00
True
Protoss
Terran
3964
-91
<BRs><sp/>GoodFellas
437 rows × 7 columns
MMR vs Elo
We’re going to need to figure out a way to connect MMR to winning probabilities. Each game won awards a certain amount of MMR which depends on the difference between the two players’ pre-match MMR. If you win against a player you weren’t expected to beat, the system awards you more MMR - and the other player loses the exact large amount.
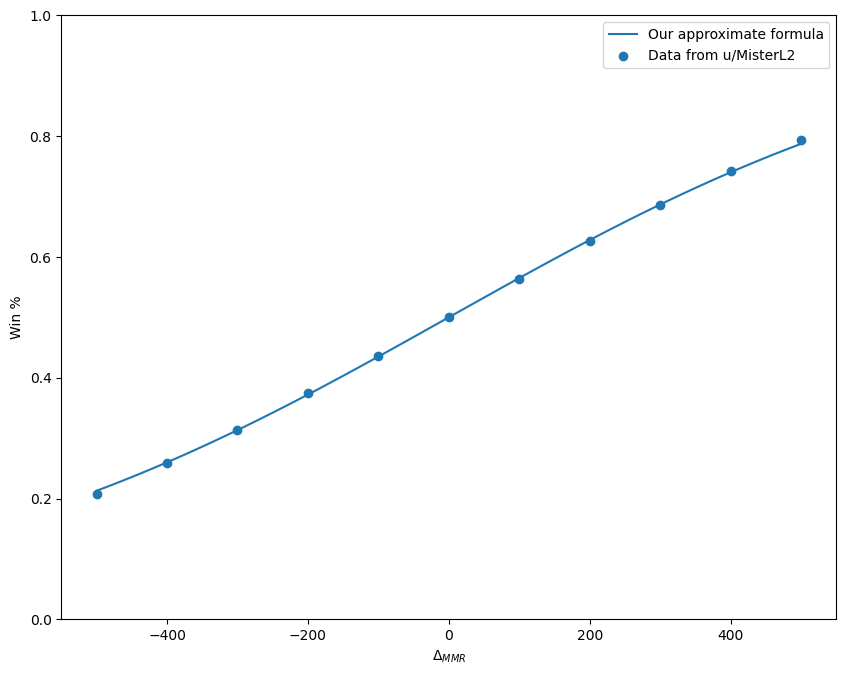
Interestingly, according to some wonderful sleuthing by u/MisterL2 on r/starcraft, MMR is basically the classic chess Elo rating, except for a simple scaling - 100 Elo is basically 220 MMR. With the Elo estimated win percentage formula depending on the difference in Elo (\(\Delta_{Elo}\)) as
there are some games at a MMR of -36400; I may be bad at StarCraft, but not that bad. I’m not willing to trust our replay parser about them, so I’ll just throw these out.
the games at a MMR of 0 are mostly custom or vs AI games. Those are recorded in replays as well. We’ll dump them too.
there are few games where I offraced as Zerg, and the game tracks a separate MMR for each race you play as. We’ll skip those as well and look only at the Protoss perspective. This
data = df[(df.mmr >0) & (df.enemy_mmr >0) & (df.race =="Protoss")]data
There are a few things we can already say from this:
Enemy Protosses at 4k MMR were already a large challenge, as I won no games whatsoever against those. This is, in fact, what inspired me to write this post!
PvT was my best matchup - there are the most wins there.
PvZ games were mostly even, though there are a good amount of lost games that I should probably have won! This seems to point to MMR not being enough to estimate my winrate properly - for example, strategical variation in Zerg play. I’m still sort of confused on what to do with a very defensive, lategame-oriented Zerg player.
Ouch. That PvP still hurts. Well, enough sulking! We’ll get back to this point later - promise - but for nowo, let’s get right to
The Bayesian model
The idea is going to be simple. I’m going to assume that:
my true MMR is some random number about 4k, oscillating at most 300 up and down from that number: \(\mu \sim \text{Normal}(4000, 300)\).
in each game, my effective MMR is a random normal variable \(\text{MMR}^n \sim \text{Normal}(\mu, \sigma)\) (where by the superscript I denote the fact that we’re sampling n of these, one per game) that includes a ton of effects, some of which can be:
the size of my breakfast of that day
time of day
enemy race
whether I’d exercised before (I should really start tracking that, come to think of it…)
the map the game is played on
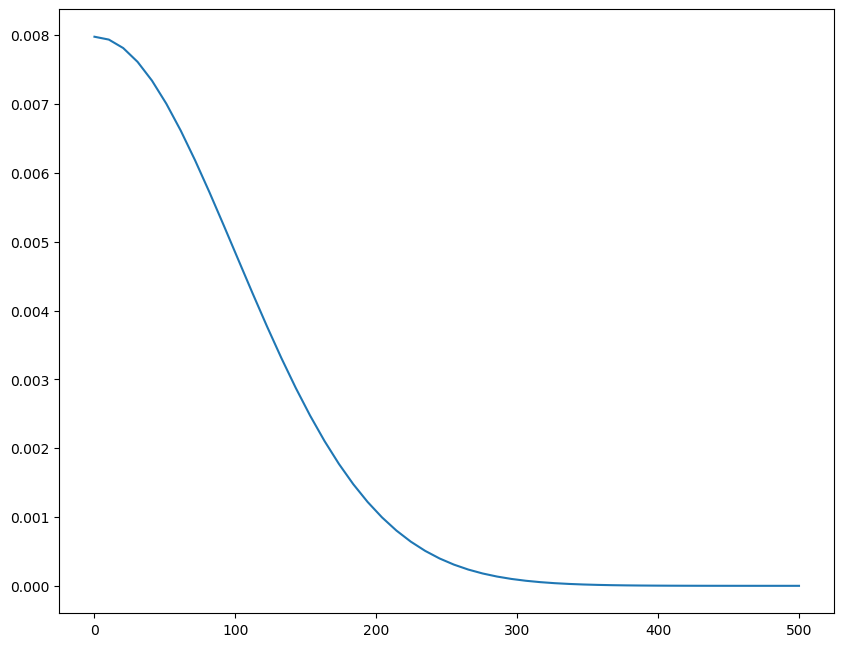
I have no idea how much my effective per-game MMR varies, so I’m just going to say the variance of MMR is going to be some positive number, and I’ll assume a half-normal distribution with a scale of 100: \(\sigma \sim \text{HalfNormal}(100)\). Let’s take a look at that distribution:
from scipy.stats import halfnormx = np.linspace(0, 500)PDF = halfnorm(scale=100).pdf(x)plt.plot(x, PDF);
which is another way of saying “some positive number, small-ish, probably not larger than 200”.
Okay, but that’s the MMR. We need some way of connecting that to our won and lost games! Luckily, we have the MMR_winrate formula: we know that the ladder system essentially models each game as a biased coin (Pro) toss (that joke is much funnier when you’re the Protoss on the ladder), with the bias being equal to the estimated winrate. The probability of a coin toss giving heads is usually modelled with the Bernoulli distribution.
Let’s now go ahead and use PyMC3 to encode that into a Bayesian model:
import pymc3 as pmimport arviz as azwith pm.Model() as bernoulli_model: mmr_μ = pm.Normal('μ', 4000, 300) mmr_σ = pm.HalfNormal('σ', 100) mmr = pm.Normal('MMR', mmr_μ, mmr_σ, shape=data2019.enemy_mmr.size)
Note the shape part - we sample one effective MMR for each game in the dataset. Now, we deal with calculating the expected winrates for our games:
with bernoulli_model: diffs = pm.Deterministic('MMR_diff', mmr - data2019.enemy_mmr) p = pm.Deterministic('winrate', MMR_winrate(diffs))
Deterministic variables are stuff that depends in a predictable way on your random variables, once you know their values. We could skip that, but I label them as Deterministic to easily track them later.
We can now add the actual data using the observed keyword:
with bernoulli_model: wl = pm.Bernoulli('win', p=p, observed=data2019.win)
And now we press the magic inference pymc3.sample button! I’ll go into details on it another time (when I understand it better myself!). In a nutshell, though, sample is going to launch a few “random walks” (Hamiltonian simulations of particle motion, technically! Those are the details I wasn’t going to explore today…) in parameter space. Ideally, these can explore a good amount of parameter value sets and find ones that fit the data well.
I’ll also wrap it in the neat arviz Bayesian visualization library.
If you’re running this live, this is a good time to put the kettle on:
with bernoulli_model: bern_data = az.from_pymc3(trace=pm.sample(2000, tune=2000, chains=4))
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 2 jobs)
NUTS: [MMR, σ, μ]
Sampling 4 chains, 1,297 divergences: 100%|██████████| 16000/16000 [00:44<00:00, 360.37draws/s]
There were 927 divergences after tuning. Increase `target_accept` or reparameterize.
The acceptance probability does not match the target. It is 0.23962550742848526, but should be close to 0.8. Try to increase the number of tuning steps.
There were 119 divergences after tuning. Increase `target_accept` or reparameterize.
There were 249 divergences after tuning. Increase `target_accept` or reparameterize.
The acceptance probability does not match the target. It is 0.6604859684507034, but should be close to 0.8. Try to increase the number of tuning steps.
There were 2 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.05 for some parameters. This indicates slight problems during sampling.
The estimated number of effective samples is smaller than 200 for some parameters.
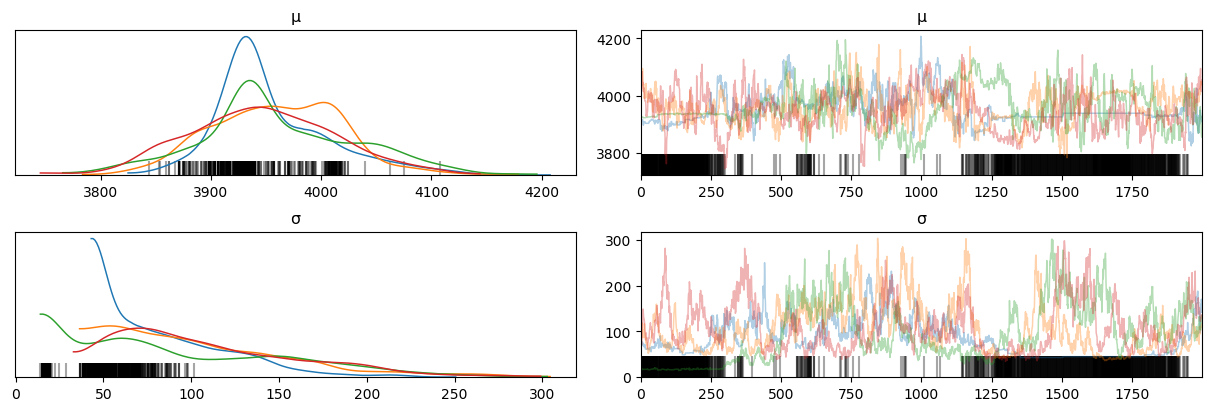
Aaaaand everything crashed. We can take a look at these results, but they won’t be pretty:
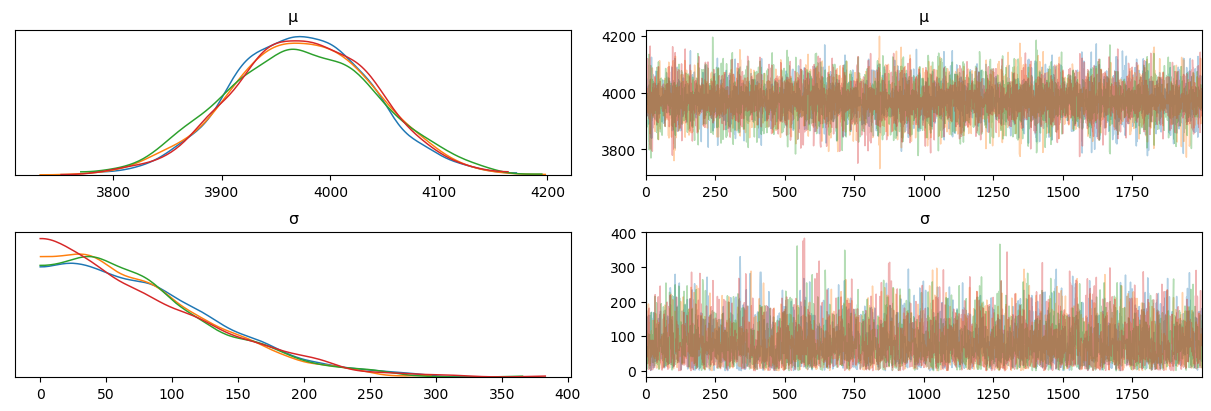
Each colored line represents each of the trajectories, with histograms of their values on the left, and actual (pseudo)time trajectories during the sampling on the right. As we can see, the chains don’t exactly agree with each other. Divergences (vertical lines at the bottom… yeah) mean that our random walkers, or probability space particles, flew off to infinity, forgetting all about energy conservation and that kind of jazz. A model with divergences is… basically, bad. They didn’t manage to sample parameters well, getting stuck in multiple regions of parameter space, with slow variations and definitely not independent steps. This completely messes up the histograms. If the chains disagree as badly as they do here, well, that’s not a model to be trusted.
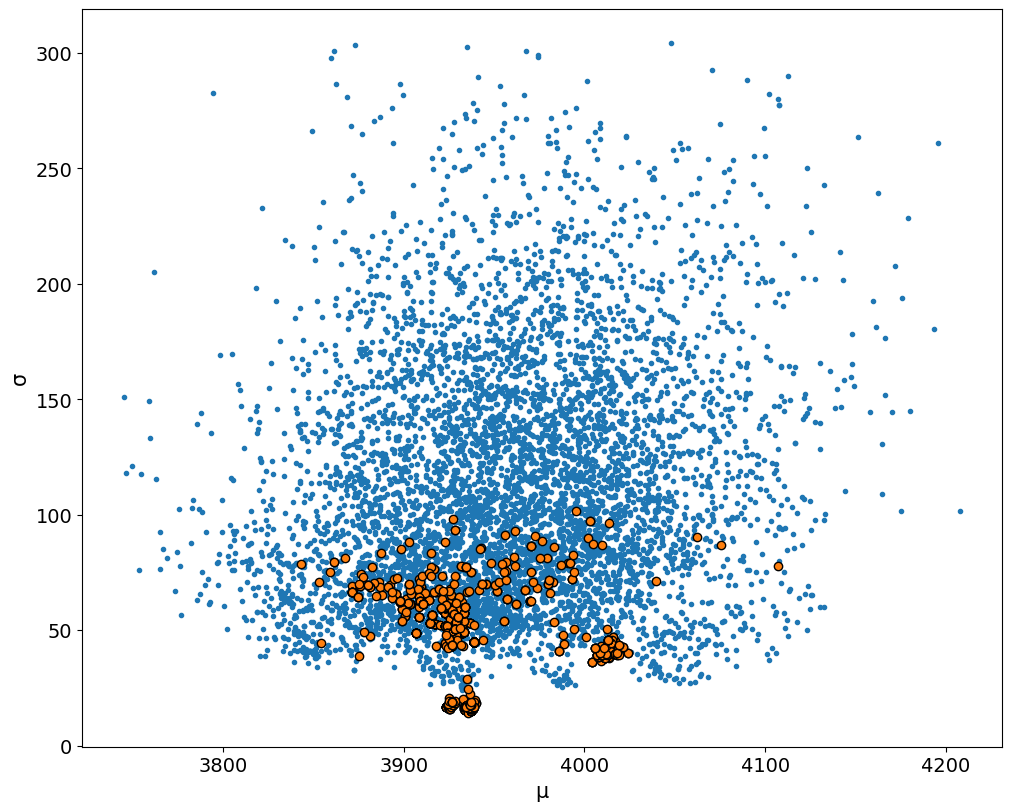
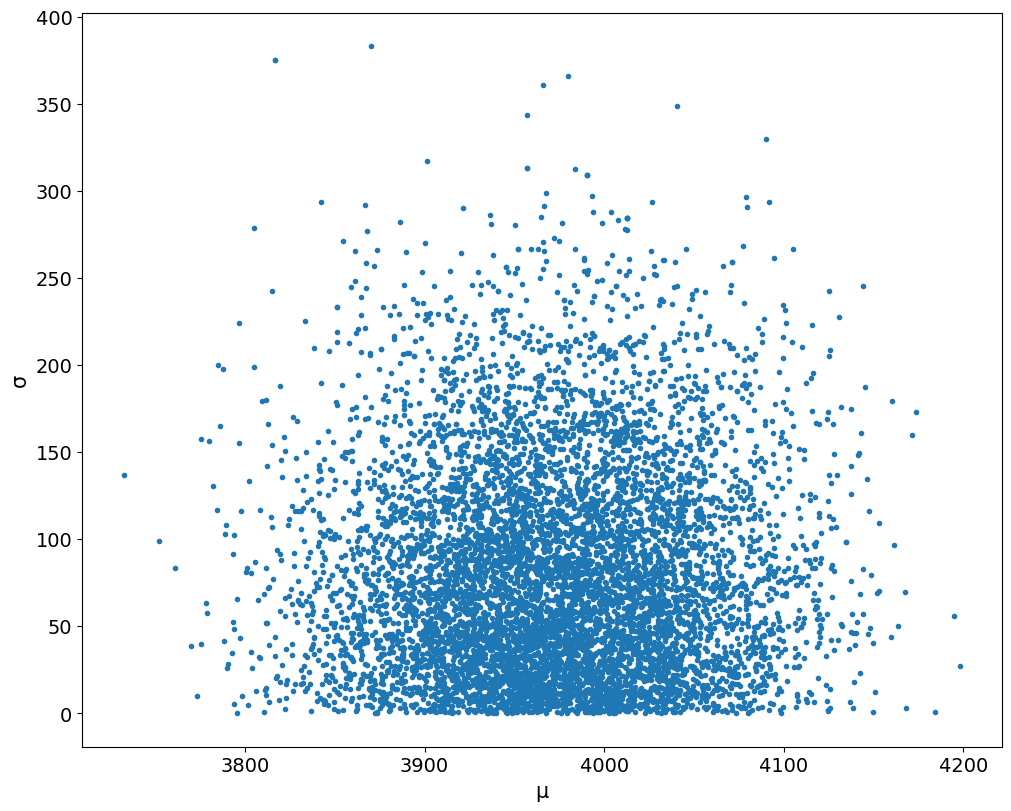
We can also look at where in particular in parameter space the model started having trouble:
Well, there’s clearly some issues at the bottom, at low values of \(\sigma\). It is, however, kind of unhelpful.
I don’t quite understand the next part myself just yet, but as I (probably not particularly well) think of it: what people usually do in this case is decouple sampling the amplitude or variance\(\sigma\) of our estimated MMR from sampling the direction and value of each particular iteration, and from the mean itself. We treat the mean as we did before:
\[\mu \sim \text{Normal}(4000, 300)\]
We’ll also take the variance as usual:
\[\sigma \sim \text{HalfNormal}(100)\]
What we’ll also do, however, is grab a set of normal variables:
\[\sigma_\text{norm}^n \sim \text{Normal}(0, 1)\]
And we’ll calculate the effective MMR per game as:
This is called a noncentered formulation, and is a big deal apparently. If I’m correct, it makes exploring variations in the amplitude easier when the possibly small variations from the separate normal helper random variables are disconnected from it, and from the mean. More about this as I know more about this.
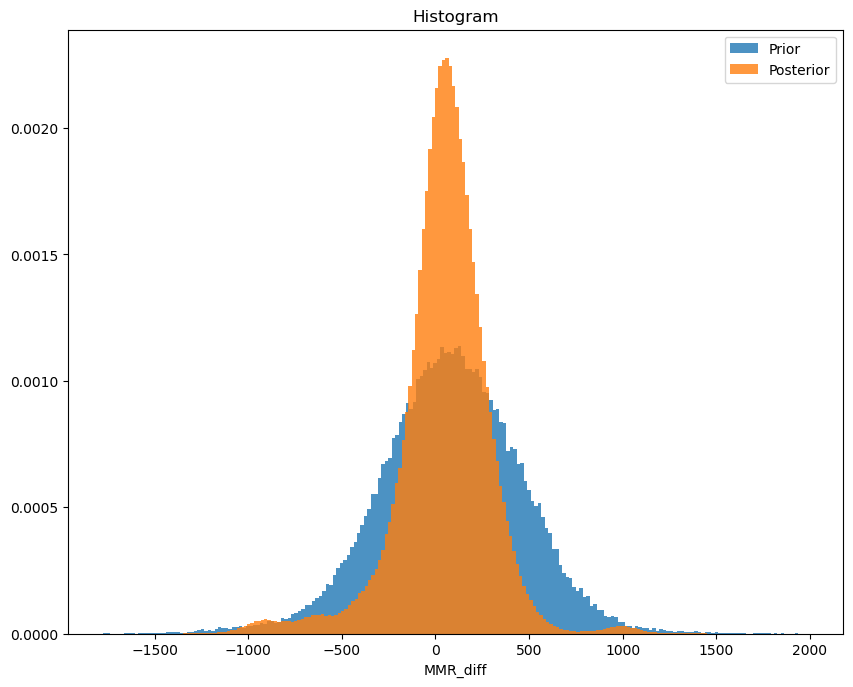
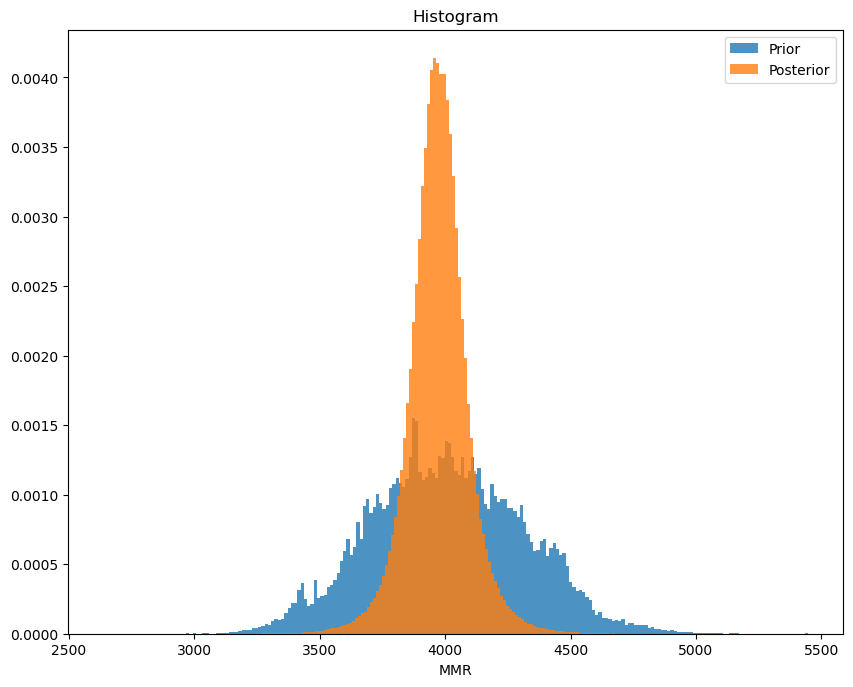
So my true MMR in 2019 was somewhere around 3973, with a standard deviation of ~65. A more Bayesian approach is saying that we can say with 97% (I’m not completely sure it’s not 94%, because of symmetry…) certainty that the true MMR is between 3850 and 4094. That’s the Highest Posterior Density - hpd - metric.
Note how this standard deviation is an okay metric for the non-gaussian \(\mu\), but completely fails to make any sense for \(\sigma\), where I’m just going to say I’m 97% sure it’s not larger than 188, with a mean of 81.
Also note that HPD means what it means - we’re 97% (or 94%, because I’m not sure about that detail!) sure that the variable is in these bounds, according to this model. The comparable metric in frequentist statistics - the \(\chi^2\) test - says… something that nobody really understands. I can find the papers on that for you if you’d like, but basically… people think it says what HPD says, and it doesn’t, really.
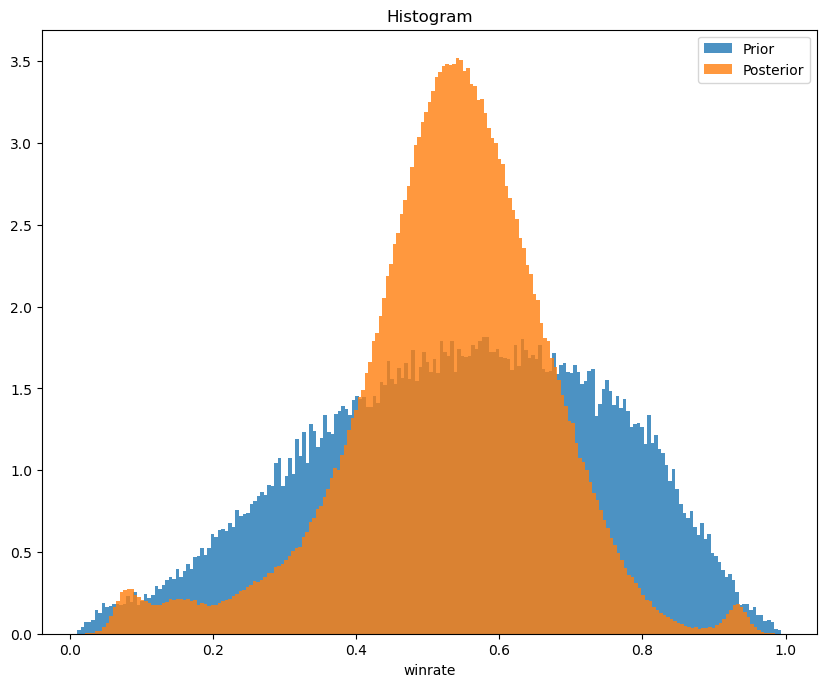
The winrate got closer in mean to 50%, which is what the system tries to optimize for. Reasonable! Note that the prior seems to not have been all that good - it predicted a winrate of more than 50%! Could have been better, but it seems to have handled the adjustment nicely.
And it definitely got more confident about my MMR being just below 4k!
Where to from here?
This was just the basic overview, and honestly - the same analysis could probably have been handled using frequentist methods. We had a good number of data points. Call .mean(), call .std(), call it a day, right?
But.
Suppose I wanted to go deeper?
Remember the point about performance varying per matchup? Well, we could find an effective MMR per race this way! Bayesian inference makes that easy. We’d have less data, as the games are split between PvT, PvZ and unfortunately PvP; but using what we know about MMR in all the matchups, we have - effectively - a prior for per-matchup data.
There are also more factors we could include. Maps? Sure! Game duration? Probably! And Bayesian inference makes it particularly simple to add those kinds of data in, once you figure out a reasonable assumption about how that data affects your play. For example, for the duration, I could postulate an equal chance of winning at each time; that’s a flat prior. Of course, it’s going to get modified when confronted with data; and that’s neat, because it lets me figure out whether I should try to avoid dragging games out, or whether I should focus more on shoring up my lacking early game play. Combine that with matchup data and you get information like “End PvZs early or lose a ton” - and now you’ve got a strong quantitative basis to support that!
But that’s a story for another day, as I just barely made it with this post today :) I’ll come back to that topic soon-ish.
In the meantime, if you have ideas about possible applications or questions you’d like answered, don’t hesitate to leave a comment below! :)