Learning my per-matchup MMR in Starcraft II through PyMC3
In this post, we’ll redo last post’s SC2 replay analysis, except we’ll take the three matchups available and infer separate MMR values for each of those.
bayes
pymc3
starcraft
python
StarCraft II Bayesian replay analysis
Published
June 20, 2020
In this post we’ll continue our SC2 replay research, started last time. You may want to go back to that and pick up on the terminology!
To recap: we used replay data from my SC2 games over 2019 to estimate a “true MMR” value and infer the size of per-game fluctuations. This time, we’ll redo that analysis, except to get something more useful: we’ll look at the three matchups I played and infer separate MMR values for each of those. Let’s dig into it!
I’ll redo the basic data cleaning steps here. If any of this is confusing, reviewing the previous post might really be a good idea - or you could ask a question below, as always!
If you take a close look, you might also find a teaser for one of the next posts in this series here :)
Let’s visualize the games on a per-matchup MMR vs enemy MMR basis. I added some fancy Altair selection magic, so you can look at winrates in specific MMR ranges.
This is where the magic starts. Where, before, we had a single MMR estimation, we’ll now have three, one for each matchup: \[\mu^n \sim \text{Normal}(4000, 300) \text{ for } n \text{ in } \{1, 2, 3\}\]
And likewise for the fluctuation value: \[\sigma^n \sim \text{HalfNormal}(100)\]
And that, honestly, is about it! When I realized it, I wanted to title this post “How Can It Be That Simple, Like, What The Hell”. But I did have to tinker with the model for a good while to find out the optimal way of doing things. It turns out the first idea I had was optimal. Who knew.
We’ll use some fancy new PyMC3 3.9 and ArviZ 0.8.3 functionality to replace the old shapes arguments with dims, for cleaner code.
Note: to reproduce, use the GitHub master release of ArviZ for now.
import pymc3 as pmimport arviz as az# fancy new functionality for xarray output - I'll explain later!coords = {"replay": data.index,"race": ["Terran", "Protoss", "Zerg"],}
We now assign the new priors for \(\mu^n\) and \(\sigma^n\), three of each - and then we’ll add a helper variable for each of the replays. Note how the new syntax is a good bit cleaner than hardcoding the shapes in.
And the next change we have to make is indexing the per-race average and fluctuation values based on the enemy races, so that each game in our dataset gets the MMR for its particular matchup.
We’ll have to assign a numerical index for each possible enemy race. We’ll choose zeroes for Terran and two for Zerg, so that, at least in indices, Protoss can be number one.
And now it’s smooth sailing from here on out! I forgot to add it last time, but PyMC3 can create a neat graph for your model using GraphViz. If I had remembered to do so, the only difference between this model and ours would be the 3 for \(\mu, \sigma\) - since we now have three of each - and adding the enemy_race as pymc3.Data.
And now, let’s sample! We’ll add a predictive prior and posterior sample: this lets us easily see what sort of data we’d see from our initial assumptions and from the fully “learned” (“taught”?) model.
Sampling 4 chains for 2_000 tune and 2_000 draw iterations (8_000 + 8_000 draws total) took 18 seconds.
There were 4 divergences after tuning. Increase `target_accept` or reparameterize.
There were 3 divergences after tuning. Increase `target_accept` or reparameterize.
Once again, we have a few divergences, but they don’t seem to say anything concrete as far as I can tell. These could be false positives; we could increase target_accept, which is basically an inverse timestep for the simulation (shorter timesteps usually mean larger accuracy at the cost of more computational time).
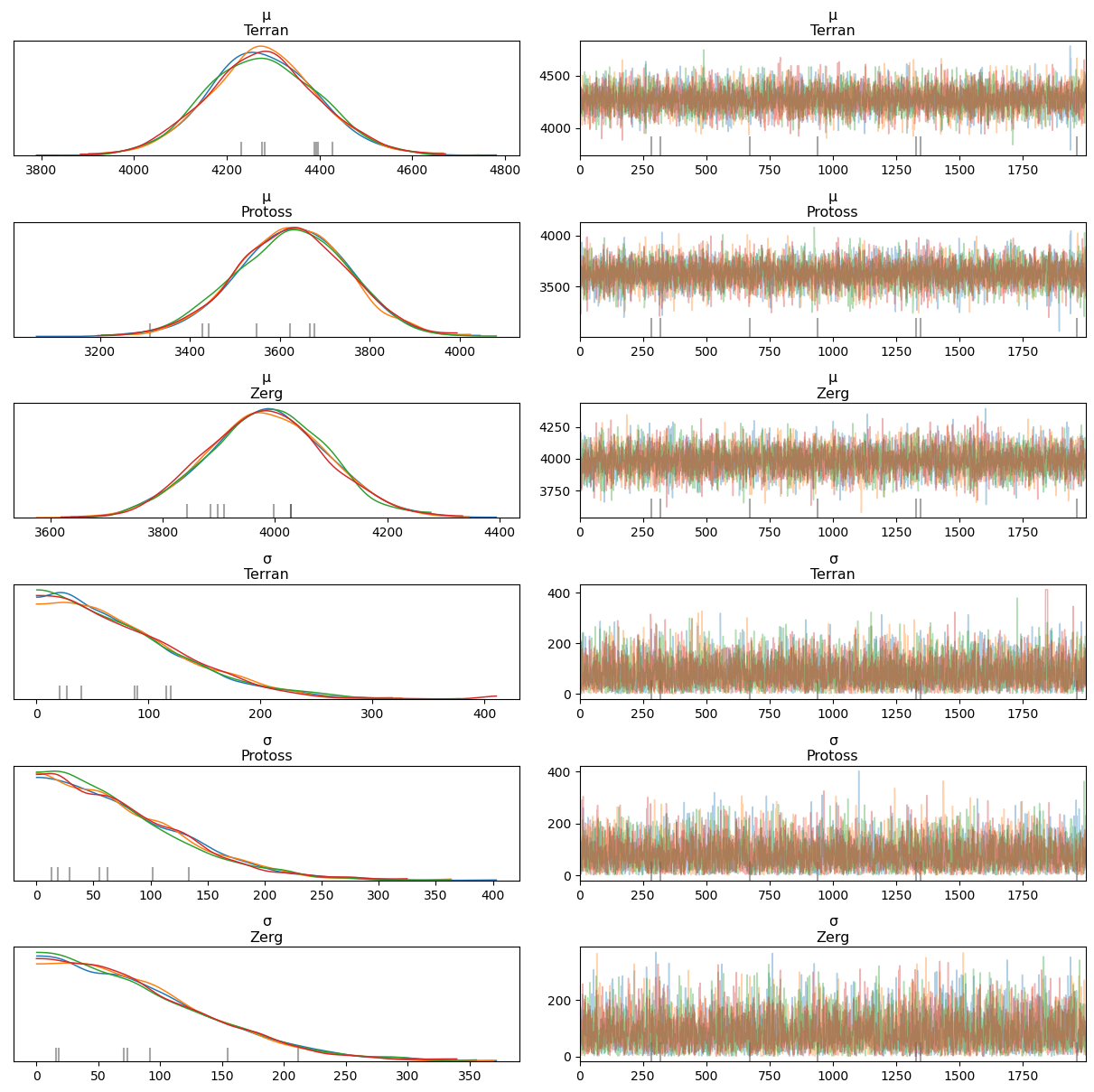
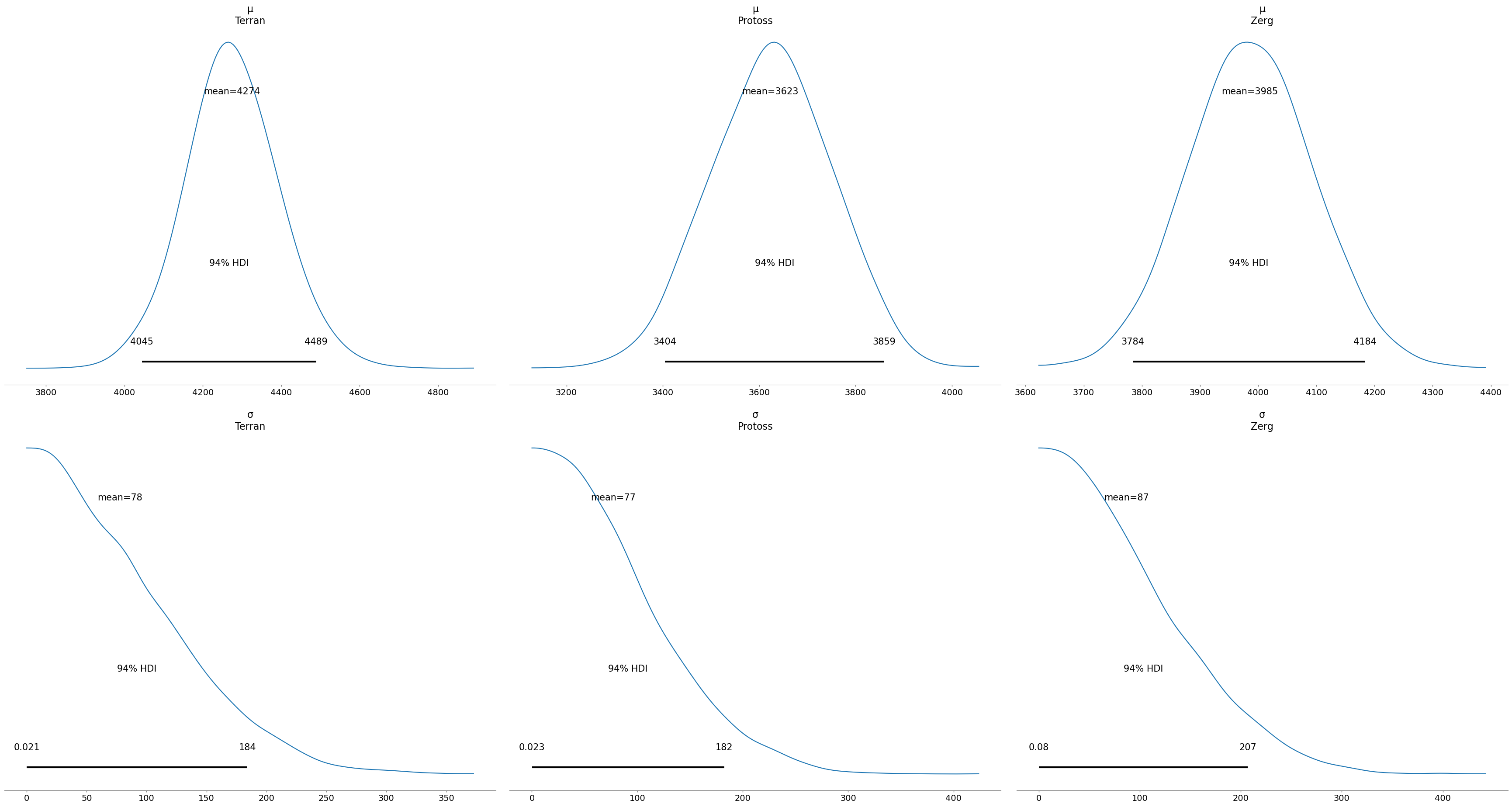
We can also plot the posteriors and the Highest Density Intervals, whose value for the threshold of 94% says that our model is 94% sure my PvT average MMR is located between 4045 and 4489:
az.plot_posterior(output, var_names = var_names);
This already shows us two things:
there are large differences in average MMR in the three matchups - as we had expected! This basically means I could go to TopTierPractice and use these MMR ranges to find practice partners at appropriate levels for the both of us. Interestingly, this means I should have been seeking better Terran players. (Note that this is last year’s data).
The versus Zerg fluctuations are a tad larger than against the other races; this would mean there are more confounding variables. Game duration could be a factor; I feel much more confident in the midgame than in the extreme lategame or against early rushes.
And this is honestly something you could start applying to your own data right now. Now, what I was going to do was to also apply a hierarchical model to this data; but, since it turns out I don’t really understand them all that well just yet, and I’m running out of time for my pre-set deadling for this post, I’ll postpone that for the next week.
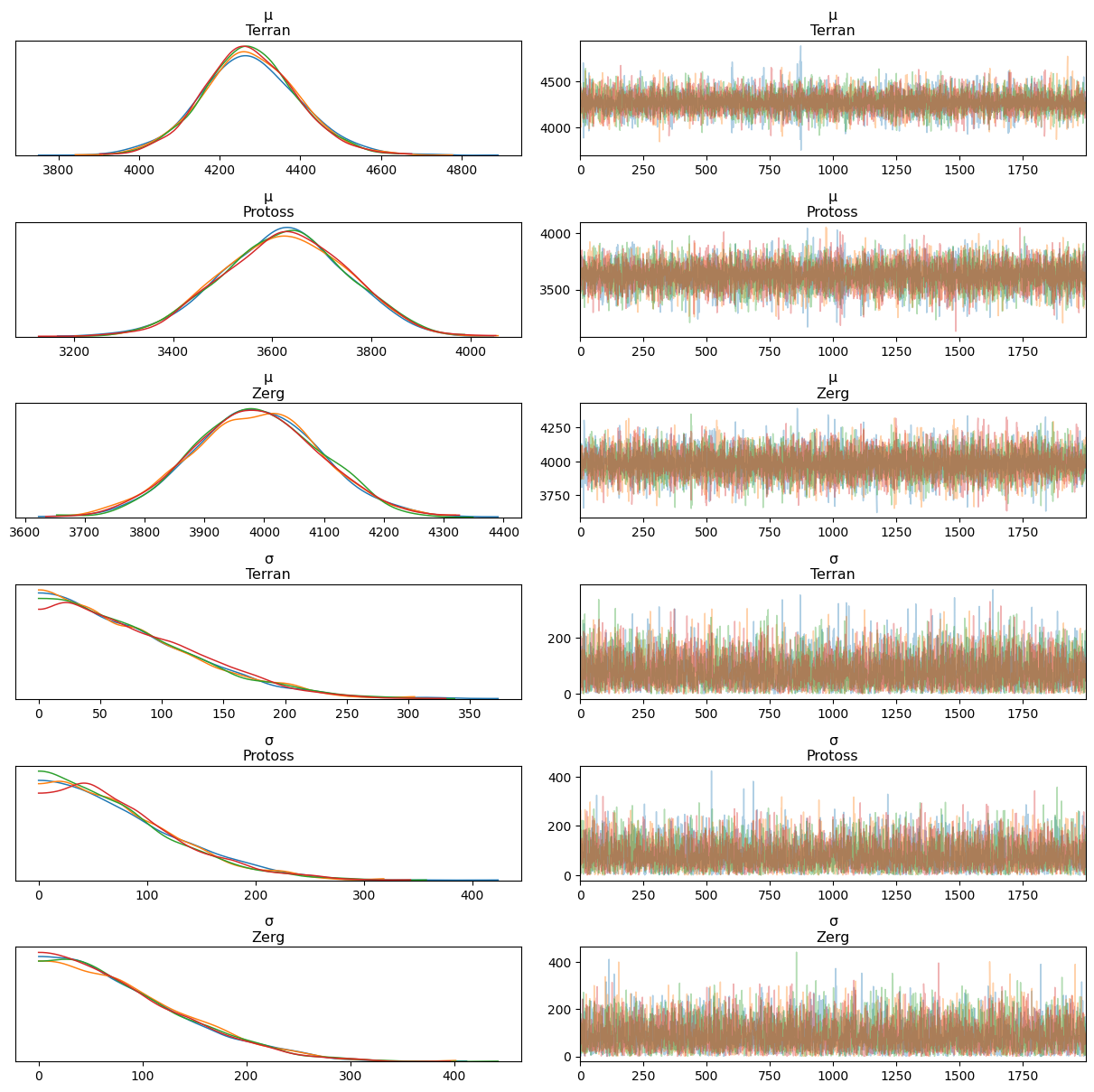
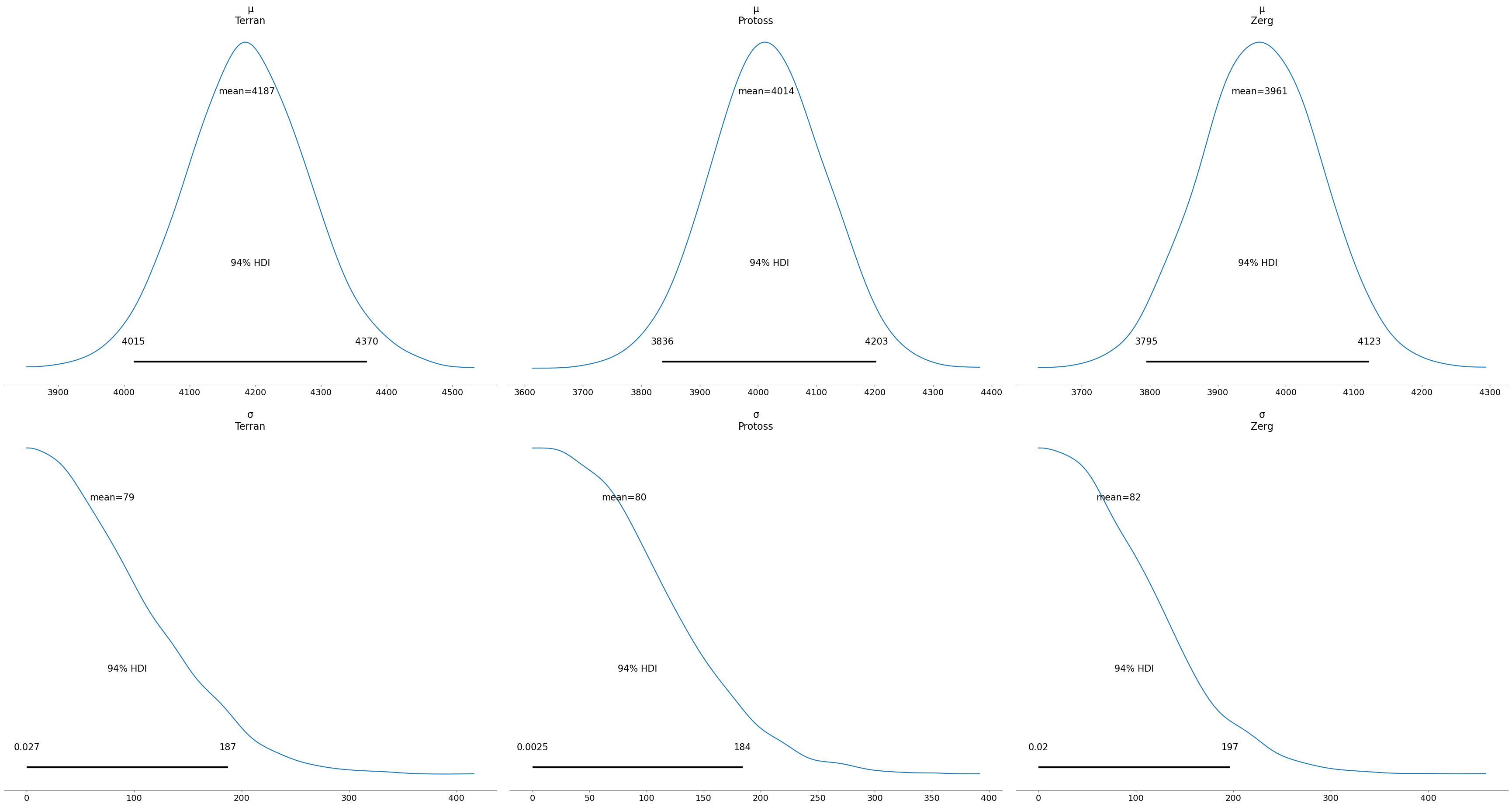
Instead, what we’ll do is take a look at the current (this year’s) data, using this exact same technique for a cheap replica of time dependence:
Analysis repeated for 2020 (easy code snippet!)
data = all_data[(all_data['time_played_at'] >'2020-01-01')]display(data)
And this seems to show I’ve grown more balanced as a player - the daily fluctuations are much more similar between games, I’ve gotten much better against Protoss, slightly worse against Terran, and my PvZ looks like it’ll need some more work. Still, I’m really happy to see the data show I’m not as bad in PvP now!
For the next post, I’m torn between a few experiments I’m running:
a hierarchical model to estimate both true global and per-matchup MMR at the same time while sharing information between the three matchups
map dependence, which is going to be easy-ish now that I know how to index variables well
actual time dependence, but I’ll have to read up more on Gaussian processes and random walks to do that.
playing around with prior- and posterior- predictive checks, which was going to be in this post, but it turns out I don’t fully understand them enough yet. This will involve a foray into xarray - the awesome data structure that stores our results.
If you have any preference, please say so in the comments; I’ll try to take it into account. Until the next time!